Website performance is no longer optional. It is one of the main reasons to choose one website builder over another. When every millisecond matters, building fast and reliable websites is not just a technical goal but a key part of your clients' business success. Strong performance drives user satisfaction, increases engagement, and improves search visibility. All of these factors are essential for growth.
In the competitive web landscape, superior site performance is key to success. It not only enhances the visitor experience but also claims to improve search engine rankings.
A high-performing website loads quickly, maintains a stable layout that prevents user frustration, and provides smooth, responsive interactions. These three key measurements, defined by Google, are known as Core Web Vitals (CWV).
Since their introduction, the Core Web Vitals have evolved, and today they are defined by the following three metrics:
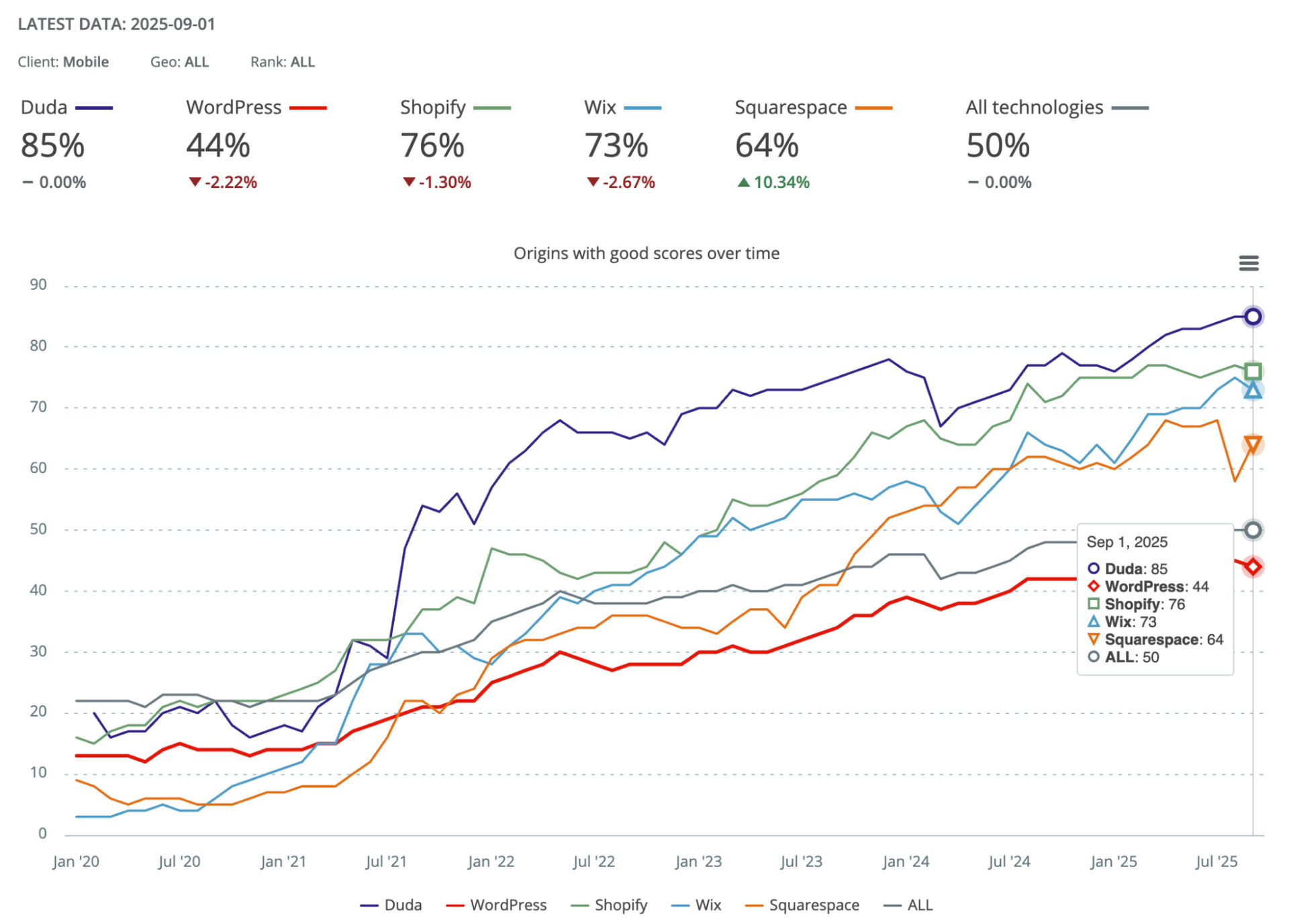
Duda leads the market in website performance. According to Google’s latest
Core Web Vitals Technology Report, an impressive 85% of Duda-powered sites achieve “good” Core Web Vitals scores, the highest among website building platforms:
This leadership isn’t by chance. It's the result of Duda’s relentless focus on speed, stability, and user experience at scale. Every optimization, from infrastructure to runtime innovations, is designed to ensure that sites built on Duda consistently perform at the top of the web.
One of the tools Duda uses to achieve these results is the
Speculation Rules API. This article explains how Duda applies the Speculation Rules API to improve future site navigation and enhance LCP scores. It also discusses the challenges faced and shares data to help you decide whether this API could improve your own site's performance.
Ready to dive in? Excellent. But first, let's understand what the Speculation Rules API is.
Speculation Rules API
From
MDN:
“The Speculation Rules API is designed to improve performance for future navigations. It targets document URLs rather than specific resource files, and so makes sense for multi-page applications (MPAs) rather than single-page applications (SPAs).”
This feature allows site authors to control the loading strategy for different pages. For example, an author can specify that when a user hovers over a link to the About page, the browser should prefetch its content. This ensures that when the link is clicked, the page's assets are already loaded, providing a seamless transition and faster page loading.
The feature replaces the
<link rel="prefetch"> hint and the Chromium-only, deprecated
<link rel="prerender">. Although it is often described as an “experimental” API, Duda has deployed it with careful rollout and monitoring, taking advantage of its support in modern Chromium-based browsers.
The Speculation Rules API offers a simple and direct configuration process. You specify a List of URLs or CSS selectors matching those Anchor elements, or rules to identify the URLs on the page, the desired strategy (prefetch or prerender), and the "eagerness" level that will trigger it.
While there are multiple implementation methods (which will be explored in more detail later), a basic implementation using a Script tag would appear as follows:
In the example above you can see the different configuration parts mentioned: strategy (“prefetch”), urls (“where”) and the triggering “eagerness” which is set as “moderate.”
You can read more about Chrome's implementation of Speculation rules
here.
Initial approach
Our strategy was straightforward: implement the
<script type="speculationrules"></script> on our runtime sites, initially under a feature flag, and then observe the outcomes. The configuration needed to be versatile enough for all sites, yet carefully designed to avoid the risks associated with prerendering pages (a topic we'll explore further in this article).
Here's the initial configuration we utilized:
We implemented a prerender rule for all paths while excluding those with potential undesired implications like
/logout, and incorporating selector matching. Although Google suggests a milder prefetch strategy initially, we opted for a more aggressive approach, anticipating greater performance benefits, and committed to close monitoring.
As we awaited the results from our Core Web Vitals monitoring tools, we started observing a growing number of complaints from the field…
Speculation Rules & Google crawlers
While investigating customer reports about unexpected URL paths, such as /logout, being crawled by Googlebot and appearing in Google Search Console, even for sites without a logout page, we identified a key connection. These paths exactly matched those configured in our Speculation Rules. This finding led us to disable the speculation feature and conduct a thorough investigation into the underlying issue.
Given the Speculation rules feature is relatively new, information online was scarce. This prompted an unconventional approach: reaching out to key individuals who might offer assistance.
Barry Pollard, a Web Performance Developer Advocate at Google and a leading expert on Speculation Rules, was a primary contact. In an age where such influential figures are accessible via numerous channels, I took a chance and directly messaged Barry on X (formerly Twitter) with a bit of "chutzpah" to inquire about our situation.
Initially, Barry was skeptical about the connection to Speculations. However, once I asserted that disabling the feature stopped the crawling of these missing paths and our internal logs showed Googlebot reaching these pages, Barry was convinced. He then conducted his own experiment, confirming the existence of a real issue, but this had no direct connection to the Speculation rules but rather to how crawlers operate. Specifically, when a crawler encounters a URL-like path in a document, whether it's an actual
href or a path written as part of a rule (as in our case), it attempts to access it. Essentially, crawlers follow anything that could potentially be a link.
Crawling of “potential links” is not a problem per-se, but does create noise in Google Search Console when the “links” fail with a 404—for example if a site has no
/logout URL despite appearing in the generic Duda rules.
Given this understanding, we sought a solution. While excluding URLs not on the site in speculation rules, or adding paths to the robot.txt file offers an immediate fix, it's not scalable for Duda. This approach would necessitate site-specific definitions and complex logic to differentiate valid from invalid paths. Our goal was a swift, universal application that would deliver immediate performance benefits across all sites.
So, Barry came up with an alternative that avoided the issue: defining Speculation Rules using an HTTP header. This way, the rules wouldn't be tacked onto the actual document, keeping them out of crawlers' reach.
Define Speculations Rules in an HTTP header
To define Speculation Rules via an HTTP header, include a
Speculation-Rules header in the site's document response. The value of this header should be a URL pointing to a JSON file (or multiple files) that outlines the rules. The content of this JSON file is identical to what would be placed within a script tag (as described previously).
An example for such header can be:
You can read more about it in detail
here.
Once the browser spots this header, it sets up the speculation rules. Now's a good time to hit pause and figure out how we can confirm these rules are actually being recognized and put to use.
Debugging Speculation Rules
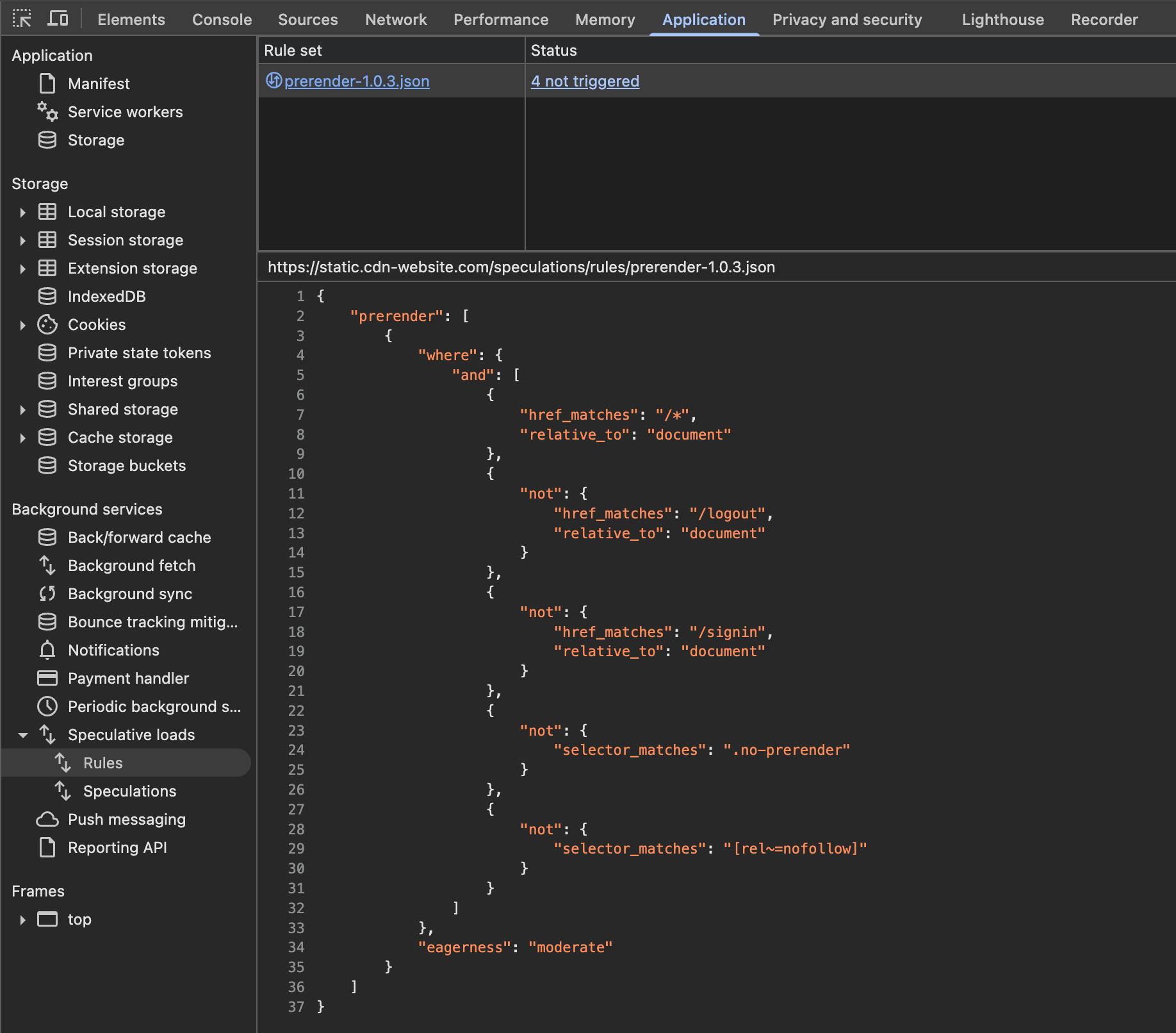
Once you've got your speculation rules set up, you can check them out by opening DevTools. Just head over to the "Application" tab and find the "Speculations loads" section. You should see something like this:
This means that our Speculation Rules were accepted by the browser. If you wanna know if these rules are being respected and acted upon you need to open the “Speculations” section, and test it.
When hovering over the links which the speculation rules have identified, the status of this path goes from “Not triggered” to “Running” and then to “Ready”, which means that they were prerendered and now ready to be navigated much quicker.
We reactivated the feature after resolving the crawling issue and confirming the speculation rules were active. We closely monitored its performance, attentive to real-world feedback, alas something was still not working as expected.
Some bumps on the way
We previously encountered an issue in Microsoft Edge for Windows, where pre-rendered pages containing videos could cause the browser to freeze and crash. This was related to Edge’s “Preload pages for faster browsing and searching” feature. The problem has since been fully resolved by the Edge team.
You can find more details about this bug in this thread;
Pre-rendered pages with videos don't load on MS Edge on Windows.
With the bug resolved, we were able to reactivate the feature and monitor its performance.
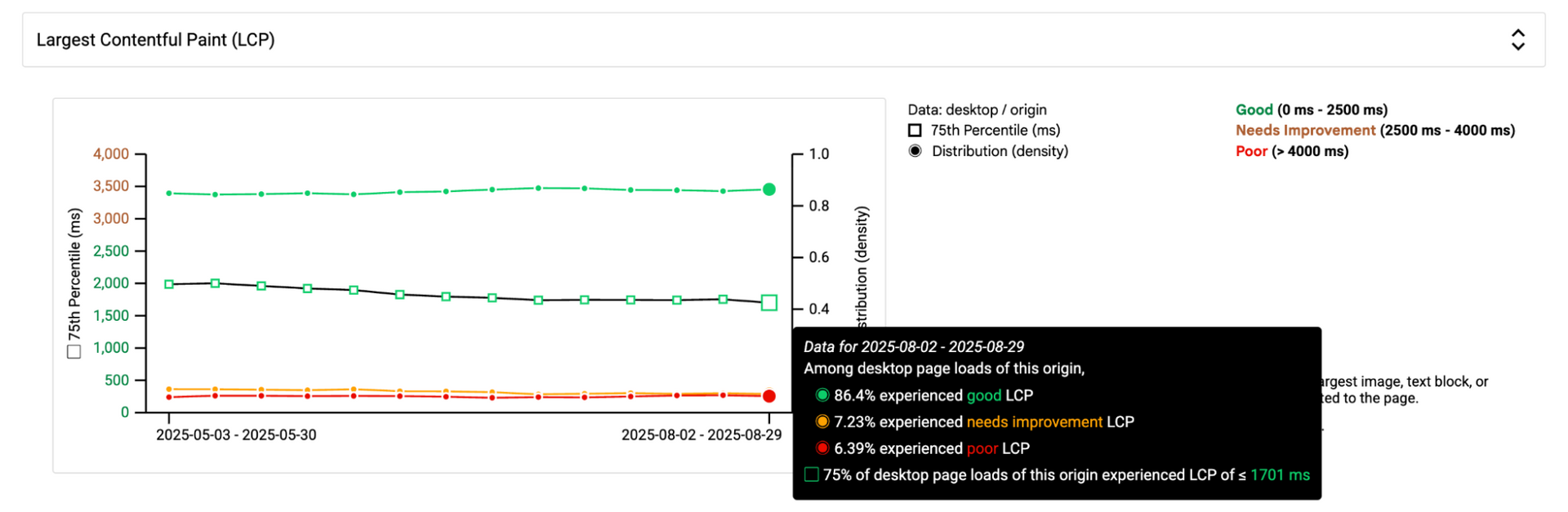
Improvements in LCP
Speculation rules are anticipated to positively impact the Largest Contentful Paint (LCP), which measures the loading speed of a page's main content. We have observed promising improvements in our internal LCP scores, a trend also confirmed by data shared by the Google team with whom we are collaborating.
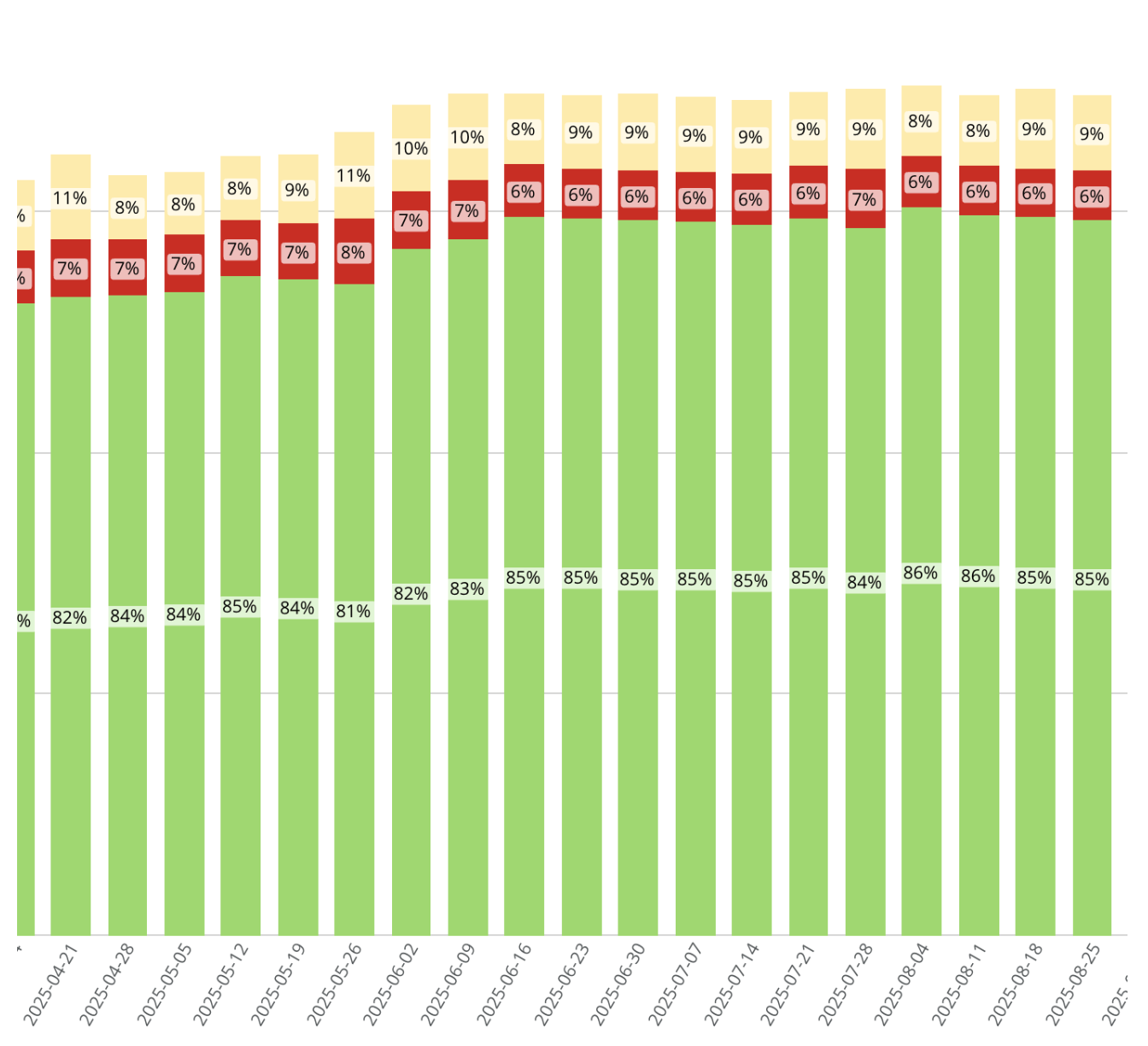
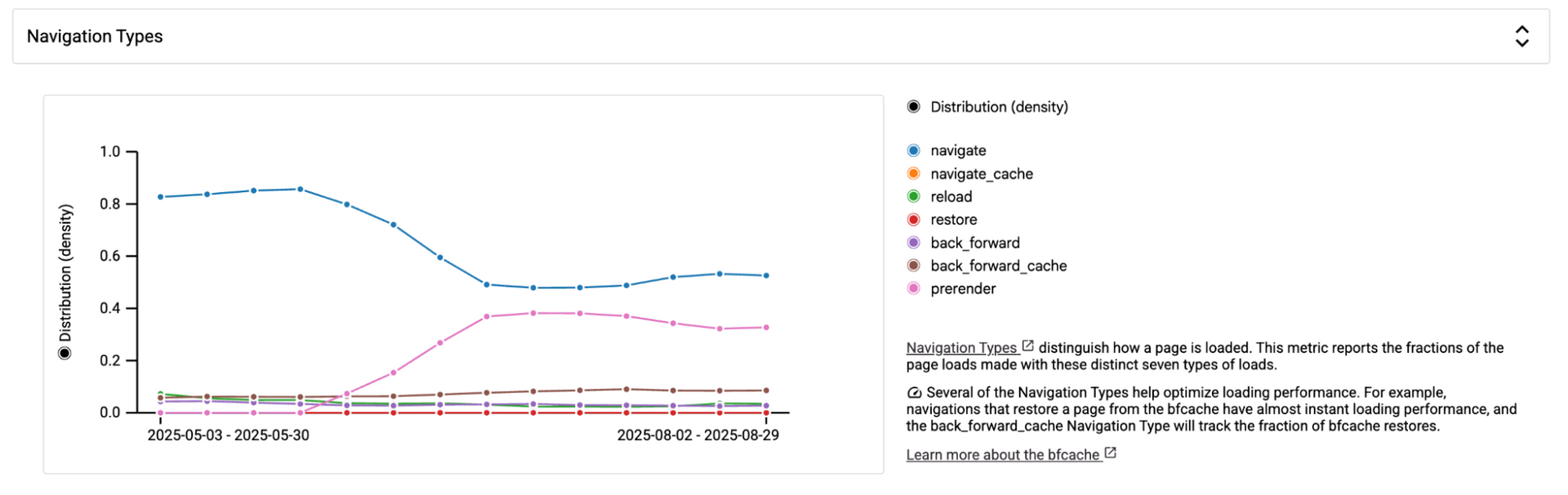
The feature, launched in mid-June, has led to a gradual improvement in LCP scores, as illustrated by the weekly distribution chart below. This gradual change is directly tied to the number of sites republished since the Speculation rules were enabled.
We used CrUX History API
Navigation Type Breakdown to measure the shift. We saw that it was shifting from "navigate" to "prerender," indicating that the Speculation rules are functioning as intended.
Navigation type categorizes how a page loads, reporting the proportion of page loads across seven distinct types. Several of these types optimize loading performance. For example, pages restored from the
bfcache load almost instantly, and the
back_forward_cache navigation type tracks these bfcache restores. Similarly, the
prerender type signifies a page that was pre-rendered, also resulting in potentially near-instant page loads.
And in addition to that the good impact it has over the LCP:
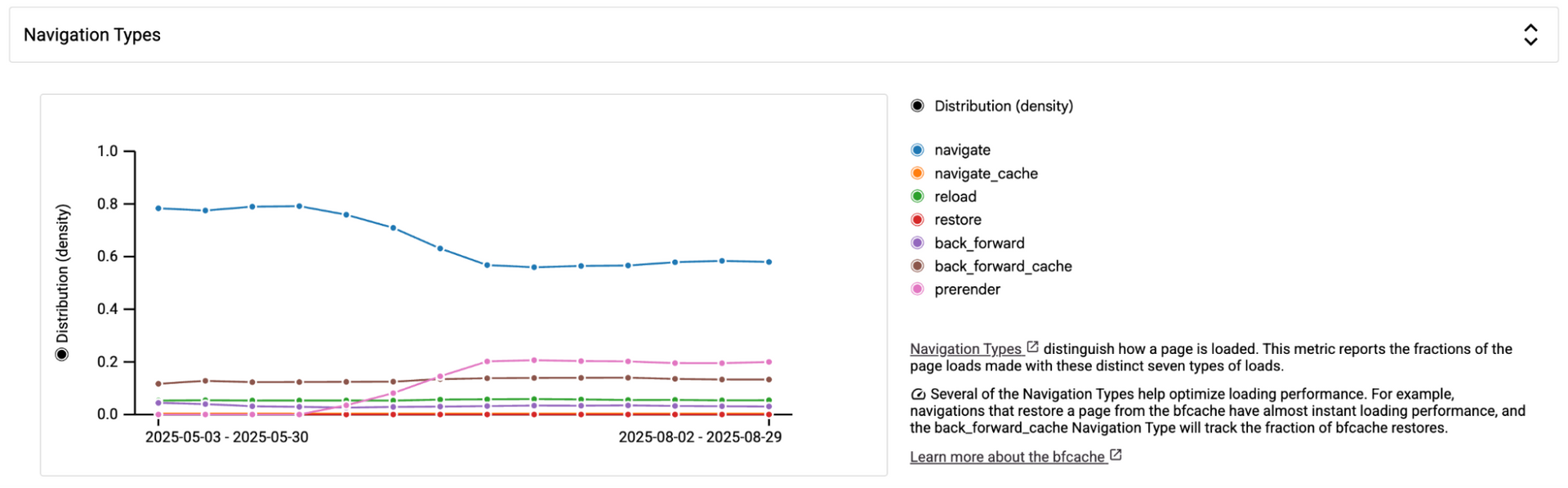
The mobile challenge
Our speculation rules are set to "Moderate" eagerness, meaning prerendering is triggered when a link is hovered over or clicked. However, this raises a question for mobile users: what happens when there's no "hover" interaction?
The Chrome team has recognized this limitation, and recently updated their Speculation Rules implementation with heuristics to help speculation on mobile in this case.
The new mobile moderate behavior involves a more complex algorithm, optimized for an effective precision/recall balance:
- The anchor needs to be within 30% vertical distance from the previous pointer down.
- The anchor needs to be at least 0.5x as big as the largest anchor in the viewport.
- We wait 500 ms after the user stopped scrolling.
This enhancement was fully rolled out on August 22nd.
You'll notice that speculation rules positively impacted mobile navigation type, though not as significantly as desktop.
What to be aware of
Pre-rendering involves the browser fetching and rendering a page's assets before actual navigation. This includes downloading and executing scripts, which can sometimes lead to unintended consequences. For instance, pre-rendering a logout page could trigger a logout action simply by hovering over its link. Therefore, it's crucial to exclude pages where pre-rendering might cause undesirable actions, which is why Duda’s default rules specifically exclude pages like the logout page.
Be aware that pre-rendering and prefetching can lead to an increase in server/CDN hits. This might result in higher traffic numbers without a corresponding increase in actual visits (e.g., hovering over a link doesn't guarantee a click). Therefore, it's crucial to monitor your server hits to ensure they align with your expectations.
Conclusion
Our Duda journey with the Speculation Rules API has been a wild ride. We hit a few bumps in the road, like sneaky crawler behavior and a video bug that seemed to have a personal vendetta against Edge browser, but our insistence on having it proved to be the right direction, and our Core Web Vitals scores see great benefit from it.
So, what's the takeaway from our Speculation Rules API escapade? While these cutting-edge features are like supercharging your website, you've got to be prepared for a few twists and turns. For other platforms and developers out there, this API, especially with the HTTP header method, can be a fantastic way to spruce up your site's performance and give users a smoother experience. Just be ready to roll up your sleeves and tackle any integration quirks that come your way!