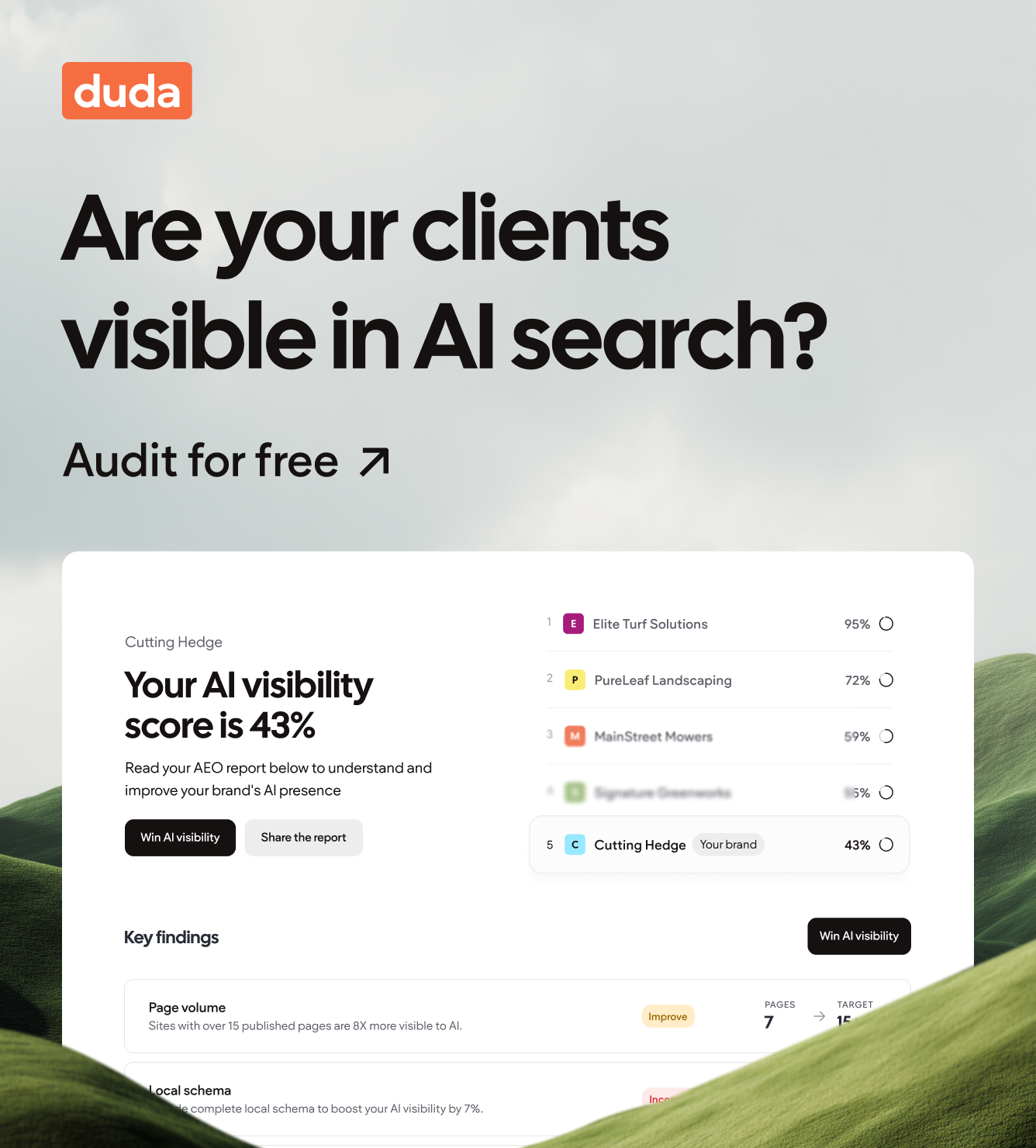
It’s common knowledge in the digital marketing industry that online discoverability is moving away from traditional methods and into
the era of zero-click content engagement. Up until recently, SEO professionals aimed for customer success stories to be indexable by the Googlebot in a way that wins visibility in search engine results for relevant search queries. Today, your case studies aren’t just indexed by search engine bots or used as collateral by sales teams. They hold the potential to serve as reliable, high-fidelity training data for AI answer engines.
Fortunately, the underlying elements that make case studies compelling to humans and discoverable by search indexing bots are the same ones that make them citable by AI models. In this guide, we’ll walk through the subtle differences and changes you can make to existing case study production and publication workflows to make your success stories (and those of your clients) satisfy the human need for narrative and the AI need for structured facts.
Interviews and numbers: Mining the ground truth
Customer success stories are typically based on interviews rather than short testimonials. This means that whoever is producing the case study needs to take on the role of a journalist—including background research, the art of interviews, and sometimes even the technical aspects of recording, filming, and editing the interview.
Simply asking a client if they’re happy and steering them toward a quote about how helpful your team has been will not yield a particularly original or helpful answer. To get an answer worthy of human and bot attention, you need to extract and communicate the “unguessable” truths and sentiment—the kind that AI cannot predict or hallucinate based on its training data.
Radically specific and unguessable details
When interviewing clients for case studies, your primary goal is to extract metrics that are unique and memorable. An AI can guesstimate (infer through probabilistic next-token generation) that an SEO agency “improved traffic” for a client. It cannot hallucinate “increased organic traffic by 4,162%” or “added 600 clients in 30 days.” These very specific metrics and numbers serve as ground truth anchors that verifiably tie your agency to the results.
Tip: In the questions sent to the interviewee in advance, gently push for numbers, percentages, and “before and after” KPIs.
Trust signals and sentiment
AI engines love numbers, but they also look for reasons to trust or distrust content according to their preset parameters. AI crawler bot algorithms are trained to detect sentiment and attribution, so a direct and attributed quote from a valid entity (like a C-level executive) serves as a valuable trust signal for the AI to validate the data points surrounding it.
Tip: Make sure that every case study features at least one champion quote that explicitly defines the problem and the solution in the client’s own words and voice.
The structure: Optimizing for extraction
The raw data from your interview needs to be organized before it can be consumed. Typically, the advice is to save the conclusion for the summary and “the best for last” since humans prefer a linear logical journey. Bots, on the other hand, just want facts fast. You can deliver both by balancing storytelling and the listing of data.
BLUF with a cheat sheet
Retrieval-Augmented Generation (RAG) systems often prioritize information
found early in the document. If your key results are buried somewhere in the middle or toward the end of the page, the AI might miss them. This is where the “Executive Summary” becomes your secret weapon. By placing a structured table of facts at the very top of the page, you reduce the cognitive load for human prospects scanning for results, while serving up a clean, structured data platter for AI crawlers.
Tip: Place a cheat sheet of facts at the very top of your case studies, with a bulleted list or table that explicitly labels your data points: Service, Key Result, Industry, Business Name, etc.
The narrative: fluency is authority
Once you have your ground truth data and structural BLUF in place, it’s time to write the actual story. While humans prefer a hero’s journey, AI models are looking for semantic associations and question-answer pairs. Here’s how you can combine both:
Reverse-engineering intent
Generic headers like 'The Challenge' are invisible to an AI looking for answers. To win the citation, you need to reverse-engineer the user's prompt. Treat your H2s as the answers to the questions your prospects are typing into ChatGPT or Google.
Tip: Change generic headers like “Results” to specific questions like “How [Client] improved their ROI” or “How [Your Brand] Helped [Client] Achieve [Impressive Number]”. Instead of simply replacing “Challenge” with “Slow Site”, go into detail like “Decreased Website Performance due to Core Web Vitals failures.”
Explicit entity naming
To help AI models pinpoint relationships between data points, you can feed their knowledge graph with defined “Entities”. Through the lens of an AI algorithm, a brand is an entity, a speaker is another, as is the author and other brands mentioned in the text. The more entities an AI can recognize, the easier it is to weave your truths into its answers to queries.
Tip: Flaunt your tech stack and name the tools and technologies you employ. This will help you associate the brand with industry giants and software ecosystems in the eyes of AI models.
Turning case studies from sales collateral to AI training data
For years, the goal was to keep users reading pages for as long as possible. Today, the goal is to provide an answer that drives action whether directly or indirectly. Winning the mentions in the new answer economy of online discoverability doesn’t mean reinventing the proverbial wheel. It means creating a better experience for busy human readers and AI models alike.
When it comes to case studies in the age of AI answers, a good success story is just the beginning. By writing, structuring, and publishing case studies rich with explicit entities, specific integers, and semantic clarity, you turn them into high-fidelity training data that AI models use to generate answers to user queries.

 Key Points
Key Points