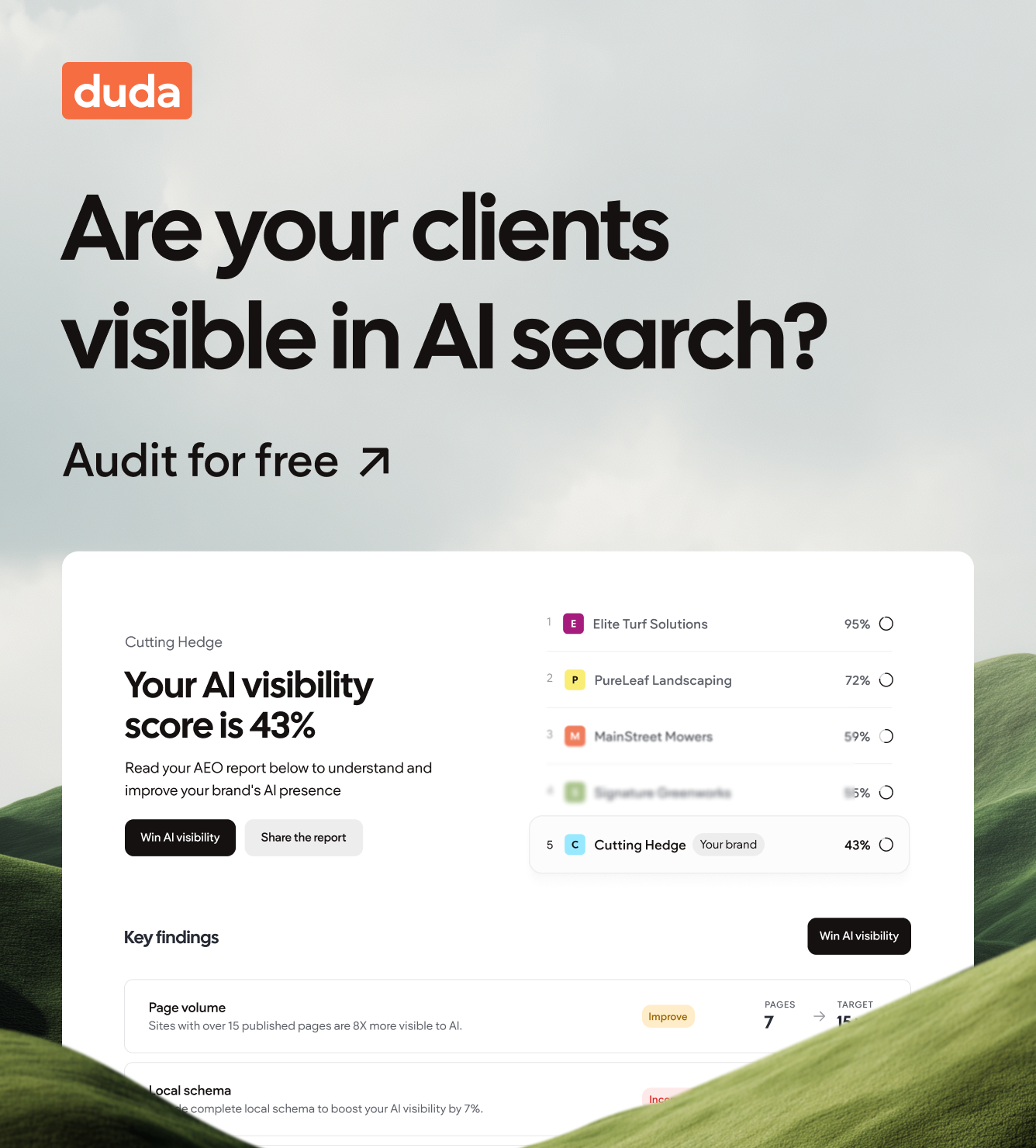
I have an orange HomePod Mini in my kitchen—their best color option, in my opinion—that I often use to play music and occasionally to set timers. Sometimes I’ll even ask it a question, to which, when the stars perfectly align, Siri will chime back with an enthusiastic “I found this on the web” before presenting its answer.
Behind the scenes, my smart speaker, like so many others on the market, is
querying Google’s index and analyzing the results—much like I might do if I were conducting the search myself on my phone. However, unlike when I search, Siri isn’t returning that familiar page of ten blue links. Instead it’s giving me an answer directly.
Here’s a more concrete example. A few nights ago I, perhaps over-ambitiously, tackled a new recipe that I believed I had all of the ingredients for. However, as I started to move through the steps, I realized that I didn't have any shitake mushrooms. When I asked Siri for substitutions, it rattled off a few options like crimini mushrooms, baby portobellos, tofu, tempe, sundried tomatoes, and eggplant. However, what I found the most interesting was that, as it was wrapping up, it also made sure to cite its source; allrecipes.com.
What was it about allrecipes.com that made Apple’s assistant repeat their content, and, more importantly, did the team at allrecipes do anything to make that outcome more likely? Did they optimize their content?
Introducing answer engine optimization
All major voice assistants—like Siri, Alexa, and the Google Assistant—are capable of answering basic questions. In this function they act as a type of quasi-“answer engine.”
An answer engine is fundamentally similar to a search engine except, unlike search engines, answer engines attempt to solve your query rather than just pointing you in the right direction. They typically draw from information published across the open web, but may also know some answers intrinsically. The Google Assistant, for instance, doesn’t need help from the web to convert liters to cups—it can just answer the question.
These tools are far from new.
Apple first released Siri in 2011 with the ability to query the web, however the technology existed even earlier as an offshoot of the US Defense Advanced Research Projects Agency's (DARPA)
CALO project, or “Cognitive Assistant that Learns and Organizes.”
A year later, Google would unveil their “Knowledge Graph” project, which laid the groundwork for a different type of query-answer mechanism; the
Knowledge Panel. They expanded upon this idea in 2014 with even more direct answers called “Featured Snippets.”
Featured snippets, knowledge panels,
local packs, and other direct responses to search queries are typically discussed in the context of “zero-click” experiences, a term that’s been gaining popularity in recent years. Understand that there is some nuance between these two topics. Not all zero-click experiences are answers, in the literal sense. When Google prioritizes a YouTube video within search, the user is not receiving a direct “answer” to their question, so to speak, but they’re also not navigating out into the open web. Instead, they’re having a zero-click experience.
Of course, none of these technologies are what modern day marketers associate with an “answer engine” anymore—although they all ostensibly are. With the dramatic release of
ChatGPT in 2022, a new, more pure, form of answer engine has appeared; the multimodal large language model (LLM).
Today, when you conduct a search using Google, you’re
very likely to receive a response from their LLM, Gemini, first, in the form of what they call an “AI Overview.” These overviews are one of many ways consumers can use AI to directly answer questions.
ChatGPT offers search functionality as well,
as does Claude, while
Perplexity was purpose built around that functionality.
Answer engine optimization (AEO), then, is the process of optimizing your website for all of these experiences, to increase the likelihood that your content is returned as the answer to a user’s query.
How do LLMs search the web?
Before we dive any deeper into the world of AEO, we should take another look at how LLMs search the web. I referenced earlier that there are other iterations of the answer engine, like voice assistants and search features. While that’s largely true, the writing on the wall is that these will all eventually become AI powered in some form or another.
The Google Assistant is slowly being
usurped by Gemini, while Alexa has
deeply integrated Claude into their Alexa+ product. Even Siri is getting a gradient-packed
Apple Intelligence upgrade,
eventually.
In fact, let’s zoom into Siri for a moment. If their marketing materials are to be believed, Apple intends to enhance Siri’s ability to answer questions with their own proprietary language models, which they refer to as Apple Intelligence. How might this new Siri answer my question from earlier about shitake mushrooms?
Well, it may just know the answer. That’s because Apple trains their models using information gathered by
Applebot, a webscraper. Applebot browses the web programmatically, clicking every link it can find and vacuuming up every piece of content it can read. This content combines to form a portion of Apple’s “training data,” the information used to create the large language model.
Most LLMs are generative pre-trained transformers (GPTs), a technology invented by
OpenAI and first shared in 2018 as “GPT-1.” It would be unfair to discuss OpenAI’s contributions, though, without first citing Google’s landmark research paper titled “Attention Is All You Need.” In it, eight scientists from Google propose “transformers,” a technology that has since become the underlying architecture for the majority of modern LLMs.
According to
Datacamp, “[Transformers] are specifically designed to comprehend context and meaning by analyzing the relationship between different elements, and they rely almost entirely on a mathematical technique called
attention to do so.”
Attention mechanisms give models the ability to “weigh” certain pieces of information, improving output quality. Transformers revolutionized attention mechanisms by enabling
multi-head attention, or the ability to focus on different aspects of the input data simultaneously. Transformers are also capable of
self-attention, the ability to weight the significance of different parts of the input independently of their position in the sequence.
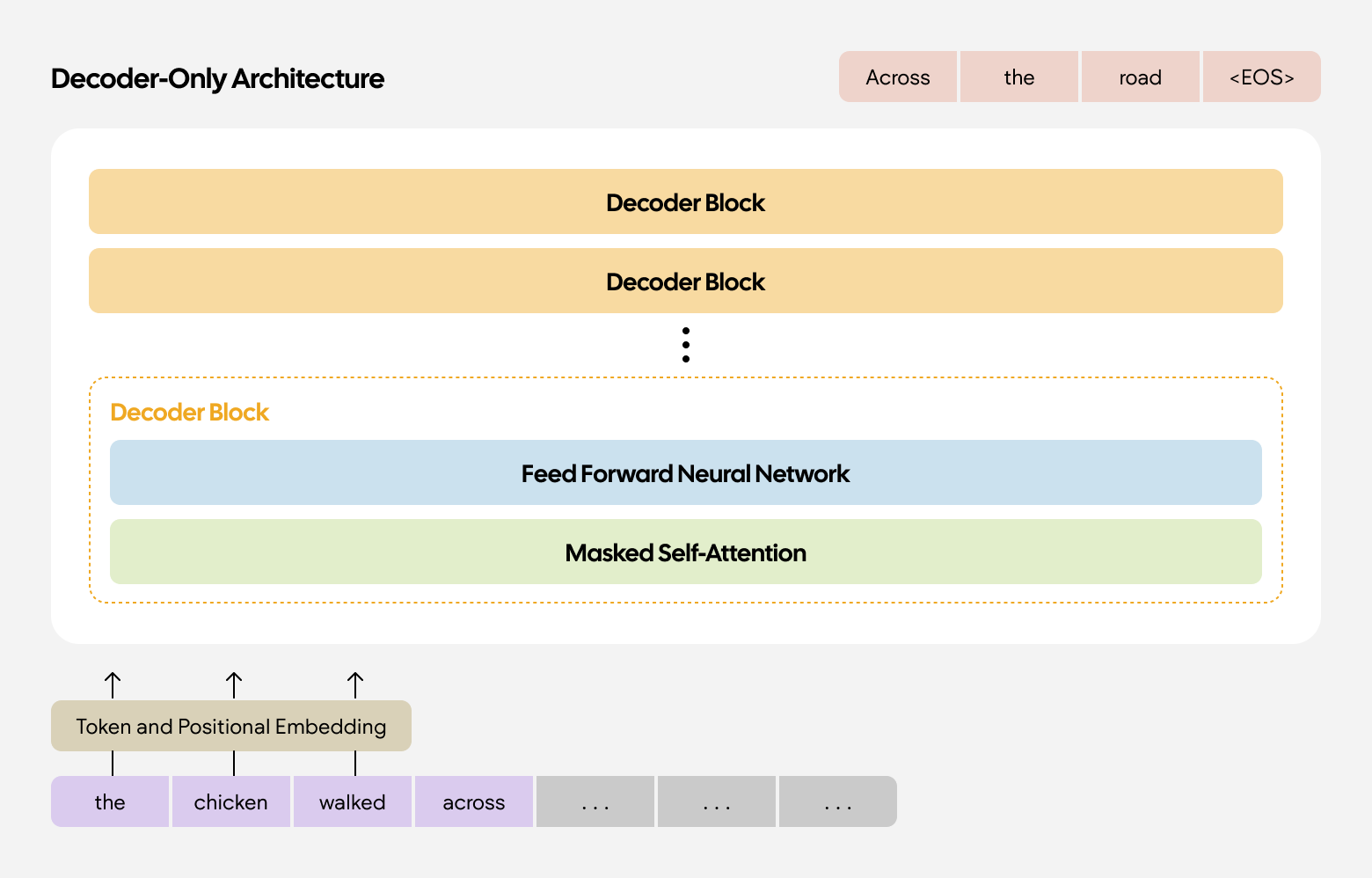
These technologies today mostly come together in what’s called the “decoder” architecture. As the name implies, your input is read by the model and is then decoded into a response. There’s a little more that happens here, like
tokenization, that we won’t get into. What’s important is that the decoder combines what we just learned about self-attention with something called a “position-wise feed-forward neural network” to generate a response.
The neural network identifies patterns and relationships between words—the fundamental way LLMs work—to create the output. To avoid wandering too much further into the weeds, this essentially means that, depending on what data was used to train the LLM, and the weights that were applied to that data, the neural network will combine words that are most likely to appear alongside one another to create a response based on what you shared with your input. This training data is often referred to as a “corpus.”
OpenAI shares
a great example of this technology on their website. In it, they suggest that a user may ask one of their models to finish the sentence “instead of turning left, she turned ___.” They claim that “before training, the model will respond with random words, but as it reads and learns from many lines of text, it better understands this type of sentence and can predict the next word more accurately. It then repeats this process across a very large number of sentences.”
They further explain that because “there are many possible words that could come next in this sentence (e.g., instead of turning left, she turned “right,” “around,” or “back”), there is an element of randomness in the way a model can respond, and in many cases [OpenAI's] models will answer the same question in different ways.”
That explains how models, like Apple Intelligence in our example above, can have some type of “intrinsic knowledge.” However, just like me and you, models cannot possibly be trained on all information at all times. There is a limit to their corpus, particularly when it comes to current events, that needs to be augmented by some kind of external source. The open web, then, is a great resource for this.
These programs start by incorporating quite a bit of information into their training data, gathered either from their own web scrapers—like Applebot or
GPTbot—or from publicly available crawl data, like
Common Crawl. Often a combination of both. That data constitutes what the model inherently “knows.”
Then, they supplement their training data with real-time information collected from search indexes, commonly either Google or Bing’s. OpenAI has their own search crawler, OAI-SearchBot, that they use in addition to Bing’s index. Information from these search indexes are included in the model input, alongside some pre-determined “system prompts.”
System prompts are typically secret, but, to be fair, so are search algorithms. They guide how the model should use the information gathered from the web when forming a response. Other parameters exist too, like how much data the model ingests from the web, which may be possible to manipulate. OpenAI is one company that allows the amount of website data used to be changed, but only
when using their API.
To put all of this together, web-augmented LLMs are combining real-time information with pre-trained model data to form a cohesive, plain language response to user queries. Responses are influenced by the index the AI model uses, where websites rank within that model, the way the content on websites is written, the LLM’s training data, and the hidden system prompts that glue it all together.
Can websites be optimized for answer engines?
Answer engines, like ChatGPT, are referring increasingly more traffic to websites. Adobe Analytics saw a
1200% increase in referrals to retail sites from generative AI, for example. As marketers, seeing reports like this raises one obvious question: can we optimize our websites for answer engines?
The short answer is an absolute, resounding yes. A universal truth to takeaway is that if things can be ranked, they can be modified to rank higher. Unfortunately, the longer, more complex answer is that LLMs are a little bit of a
black box.
I mentioned earlier that LLMs are trained on increasingly large corpuses of data. The raw training set for
OpenAI’s GPT-3 was a whopping 570GB of compressed plain text data, refined from an initial 45TB of data. The training process uses that data to form trends, something we discussed earlier in the article. How those trends are determined, and the conclusions the model finds, and how it may answer a question, are exceptionally difficult for humans to determine given the overwhelming size of the data.
“It’s one of those weird things that you know, but you don’t know how you know it or where you learned it,” says
University of Michigan Associate Professor of Electrical and Computer Engineering Samir Rawashdeh, who specializes in artificial intelligence. “It’s not that you forgot. It’s that you’ve lost track of which inputs taught you what and all you’re left with is the judgments.”
OpenAI fine-tunes their models to make answers a bit more predictable using, what they call,
Reinforcement Learning with Human Feedback (RLHF). However, this process isn’t perfect, and models can still respond in
unpredictable ways.
So, if models are unpredictable, and if we don’t necessarily know “why” they answer the way they do, and if their answers can change each time they’re promtped—how can we optimize our content?
Well, a few researchers at Princeton had that exact question. They published a paper in August of 2024 titled “GEO: Generative Engine Optimization” that attempts to prove that content can be optimized for modern AI search experiences.
This is a phenomenal paper for marketers, one that I won’t force you to read. In it, they find that websites can be optimized, and that this optimization process is different from typically accepted SEO practices. There were limitations to their research, though, that are worth noting.
The first, and perhaps most important, limitation they note is that AI search experiences are continuing to evolve. On April 29th, 2025, OpenAI released
a significant update to their search experience that embeds new inline shopping actions. That won’t be the last update. Of course, if you’ve been doing SEO long enough to see a few Core Updates shake up your rankings, you’ll find this miasma of uncertainty pretty familiar.
They also note that they were unable to determine if their so-called “GEO” efforts proved detrimental to traditional search engine performance. At the time of publication, there is no consensus on whether or not GEO/AEO and SEO compete. What we do know is that there is some overlap between the two, which we’ll discuss below. Whether they diverge or not is yet to be determined.
How can I optimize my site for answer engines?
Our advice is based on published findings from a team of researchers at Princeton in late August of 2024. AI search is in its infancy and accounts for
less than 1% of all website traffic, on average—so don’t sweat all of this too much! If you’re doing any SEO, you’ll find much of this familiar, with a few key differences. Let’s dive right in!
Your website needs to be discoverable
This is the most fundamental piece of advice for SEO and AEO alike. Nothing else you do matters unless your website is discoverable. That means you do not have any “no-index” tags set for pages you’d like to see indexed, and you aren’t excluding any important crawlers in your “robots.txt” file.
If you’re building on Duda, all of this is true by default. In fact, we go above and beyond by employing the
IndexNow protocol, which informs participating search engines of changes to your sitemap every time you hit publish.
IndexNow is just as much a crucial component of AEO as it is SEO because LLMs still rely on traditional search engine indexes to inform their answers. If your site isn’t indexed, it won’t show up.
Your content needs to be reachable
In the realm of search engines, this is called “technical SEO.” It’s the architectural decisions you make when building your website, both frontend and backend, that determine how easy it is for a program to “crawl” it.
As a refresher, crawlers work by scanning a page of a website, reading all of the content, then following all of the links. The process repeats until there are no more links left to follow. When you have a page on your website that isn’t accessible by any links, we call that an “orphaned page.” It cannot be crawled, which means it cannot be indexed, which means it will not appear in search or answer results.
Virtually all of the fundamentals of technical SEO apply to AEO since, again, these LLMs rely on traditional search indexes for their answers. If you’re building on Duda, we handle most technical SEO
out-of-the-box, while offering a variety of tools, like the
Link Checker, to make the final mile as easy as possible.
Your content needs to be written for AI
Here’s where things start to get LLM specific. Princeton’s research found that the way you write your content impacts how it appears in answer engines based on two key metrics:
Position-Adjusted Word Count and
Subjective Impression. These are your new performance metrics for the age of AEO.
Position-Adjusted Word Count, as it sounds, combines the total word count of the LLM’s output with your content’s position within the response to create something standardized and comparable across many responses. Subjective Impression is an, unfortunately, subjective measurement encompassing seven aspects:
- Relevance of the cited sentence to the user query
- Influence of the citation, assessing the extent to which the generated response relies on the citation
- Uniqueness of the material presented by a citation
- Subjective position, gauging the prominence of the positioning of source from the user’s viewpoint
- Subjective count, measuring the amount of content presented from the citation as perceived by the user
- Likelihood of the user clicking the citation
- Diversity of the material presented.
According to the paper, “these submetrics assess diverse aspects that content creators can target to improve one or more areas effectively” and were evaluated using OpenAI’s GPT-3.5 “following a methodology akin to that described in
G-Eval.”
In simpler terms, subject impressions are subjective in the sense that the LLM itself is the judge, not the researchers.
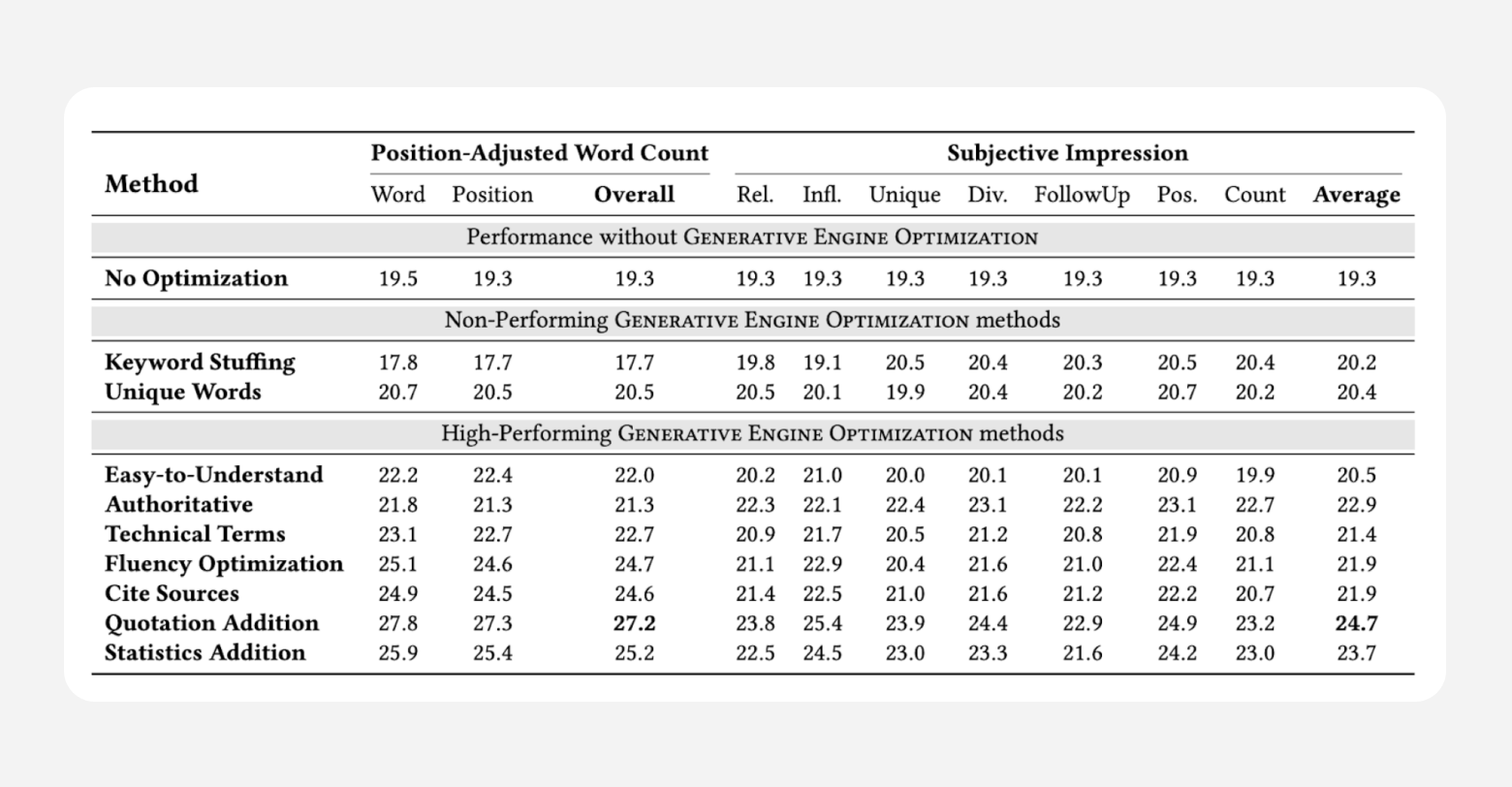
With all of this in mind, here were their content findings.
Let’s work through that table, step-by-step. Note that the most important columns here are the bolded “Overall” under Position-Adjusted Word Count and the bolded “Average” under Subjective Impression, with higher numbers meaning better performance.
We see that traditional “keyword stuffing” practices actually cause content to perform worse in LLMs. While this may imply that AEO and SEO best-practices compete with one another, it’s been known
for quite some time that keyword stuffing is becoming less effective in search anyway. If you’ve been waiting for a sign to ditch that practice, let this be it.
Content that is easy-to-understand, authoritative in tone, technical in tone, fluent in style, ripe with citations, flush with quotes, and full of statistics does seem to perform better than content without, although not necessarily all-together.
The addition of quotations, citations, and statistics lead to the highest performance boost across a wide range of categories; 30-40% on the Position-Adjusted Word Count metric and 15-30% on the Subjective Impression metric.
The paper also notes that “stylistic changes such as improving fluency and readability of the source text (Fluency Optimization and Easy-to-Understand) also resulted in a significant visibility boost of 15-30%.”
Together, this confirms that it’s not just the content itself that matters, but how the content is written.
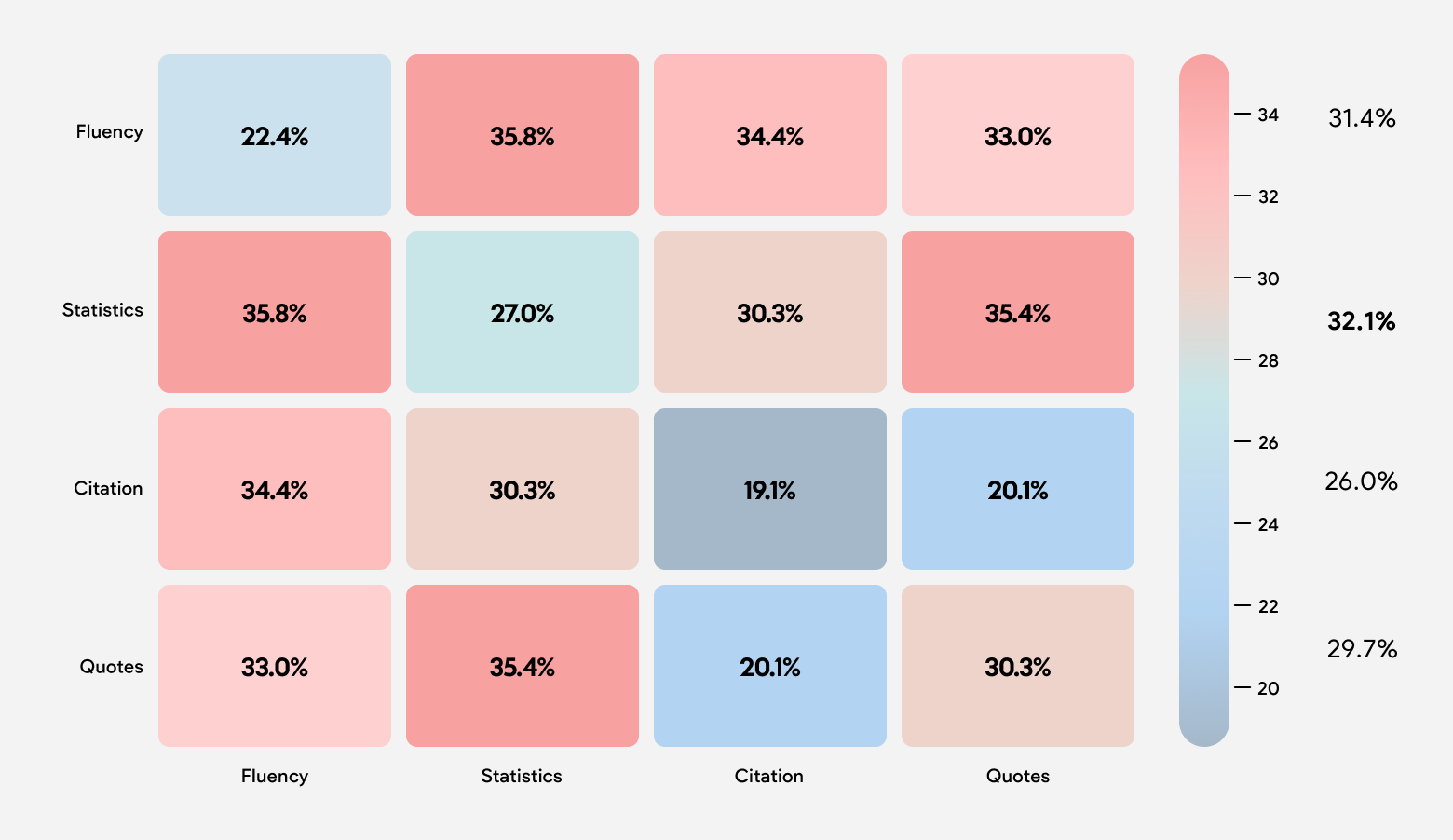
When combining optimization methods, Fluency Optimization and Statistics Addition performed the best, as shown in the graph below.
There’s an argument to be made that this is how we should be writing content anyway. While the paper does seek to create a technical framework for persuasive writing, it should come as no surprise that copy that flows well with meaningful citations and few cliches performs well.
For SEOs, this is the ultimate extension of Google’s
E-E-A-T initiative. LLMs are seeking, and prioritizing, well written content, likely because their training data is professionally written as well.
In the paper, the researchers compare two pieces of written content. The first says:
“The Jaguars have never appeared in the Super Bowl. They have four division titles to their name.”
The second modifies this statement to make it more authoritative. It now reads:
“It is important to note that The Jaguars have never made an appearance in the Super Bowl. However, they have achieved an impressive feat by securing 4 divisional titles, a testament to their prowess and determination.”
When their LLM was asked “Did the Jacksonville Jaguars ever make it to the superbowl?,” the more authoritative phrase performed 89.1% better. A lovely byproduct is that this is a better sentence for human readers, too.
In another example, the researchers add a citation to the following sentence, increasing its performance for the query “What is the secret of Swiss chocolate” by 132.4%.
“With per capita annual consumption averaging between 11 and 12 kilos, Swiss people rank among the top chocolate lovers in the world (According to a survey conducted by The International Chocolate Consumption Research Group [1])”
Again, just like before, not only is this a better performing piece of content for AI ranking purposes, it’s a more persuasive piece of content for human readers as well. Distilling their advice, we’d recommend following a journalistic style when writing. Include, when appropriate:
The paper notes that their work “serves as a first step towards understanding the impact of generative engines on the digital space and the role of GEO in this new paradigm of search engines.” That’s to say, we’re only just beginning to see what AEO/GEO may become.
Today, though, all of those English teachers who got onto their students for using a passive voice must feel pretty vindicated right now.