Over the past couple of months, Duda has introduced a new cache service into our runtime sites architecture.
A cache is a component that allows quick access to frequently used data. In our case, we store rendered sites in cache so future requests can be served as quickly as possible.
Previously, Duda used
Redis as our cache layer. When we rendered a new page, we stored the results in cache and this meant the visitor's next request for the same page could be answered quickly without rendering the page again.
Cache is controlled by a Time To Live (TTL) parameter which sets the time when data becomes invalid. In our case, we used a TTL of 2 hours, which meant every 2 hours we had to render the page again. Using this approach, we achieved a 50% request to site hit rate, and our general system performance in terms of response time was pretty good.
However, this approach had some drawbacks:
First, rendered pages were saved for just 2 hours. Why only 2 hours?
This was the first thing we wanted to address with our cache service solution. When we increased the TTL to 5 hours, we saw some increase in hit rate, but this also introduced some eviction events in our Redis cluster, meaning the cluster did not have enough room for all the data we wanted to store. This left us with two choices: (1) we could resize the Redis cluster; (2) we could decide not to use Redis for rendered pages.
Second, in case of a failure in one of our servers (caused by flows that cause CPU spikes, database load or some other crash), our runtime sites were affected immediately.
With these two drawbacks in mind, we thought about a new cache solution to serve our rendered page.
Our two KPIs were to extend the cache time from hours to days, and to make the system resistant to downtime and slowness, so rendered sites would continue to perform as usual.
Moving from Redis to Amazon DynamoDB
Redis is an in-memory cache service. As a caching solution, it delivers very high performance but is very expensive. In order to increase the TTL from hours to days, we needed to save much more data, hundreds of GB of rendered pages, which makes this solution impractical.
We decided to try
Amazon DynamoDB as persistence storage for the rendered pages. DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale.
The rendered pages were saved to DynamoDB with its TTL feature and it did an excellent job. It allowed us to increase rendered page TTL from 2 hours to 1 week. Additionally, because DynamoDB stores the data in disks and not in memory, it has the benefits of lower cost.
The drawback of storing data on a disk is that it is much slower than in-memory. However, Dynamo is still really fast and we also added DAX (Amazon DynamoDB Accelerator) which is a cache layer above Dynamo that gives us the same performance we got with Redis for the 2 hour cache, while all the resources are stored in Dynamo for a few days.
This solved the first issue, increasing cache TTL from 2 hours to several days. Nothing prevents us from increasing it to months; we won’t see eviction in Dynamo and more data will not affect performance.
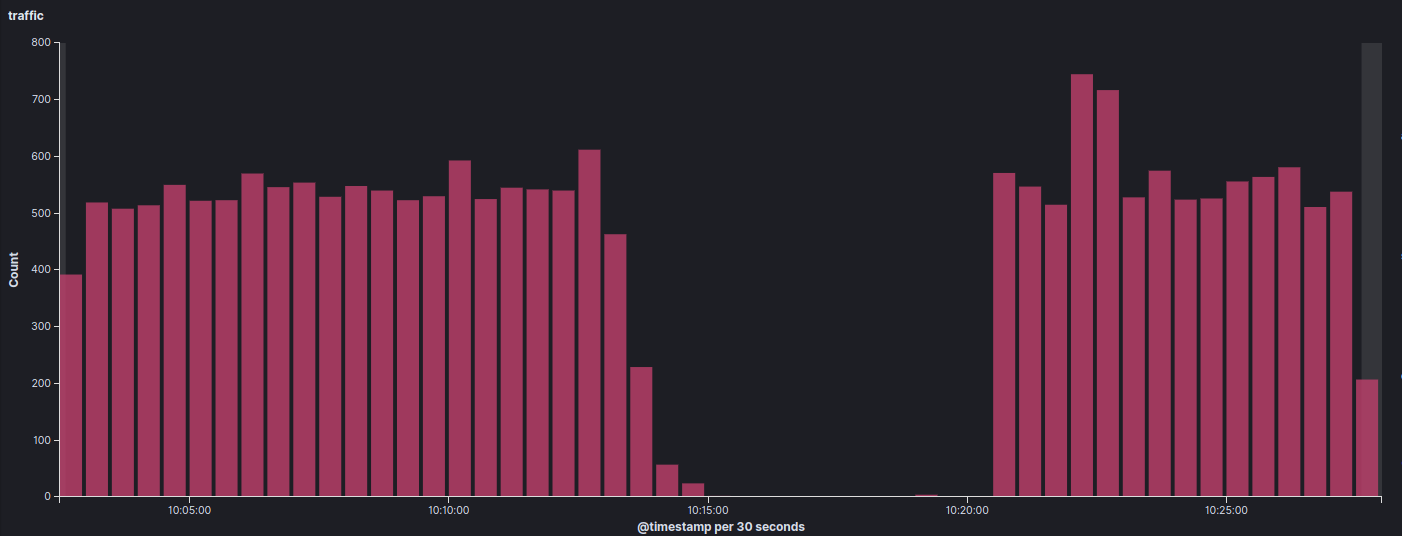
After some calibration, we achieved a hit rate of 85%.
This graph shows the hit rate over the week.
Dedicated servers for resolving cache requests
The runtime server is the one that responds to rendered sites and all requests that come from published sites. In addition, these servers go through deployments of new code every day. Any failure in these servers, or any bad code that does heavy calculations, can immediately affect sites, even rendered sites that are already cached.
To solve this problem, we decided to create new servers that will serve data from the cache.
This is the only thing that this server is responsible for and it does it as quickly as possible. These servers are fully scalable and proactively respond to changing traffic.
When such a server receives a request for some page, it tries to find a rendered version of this page in the cache. If the page exists, it is served immediately. Otherwise, we pass the request to the runtime server, and it renders the page and caches it for the next time it is requested.
This breakdown to serve page vs render page gives us the solution for the second problem. Any new code or problem that happens to the runtime server will not affect most site traffic.
When such an incident occurred in our runtime servers, we had an excellent opportunity to see how the new cache service helped us.
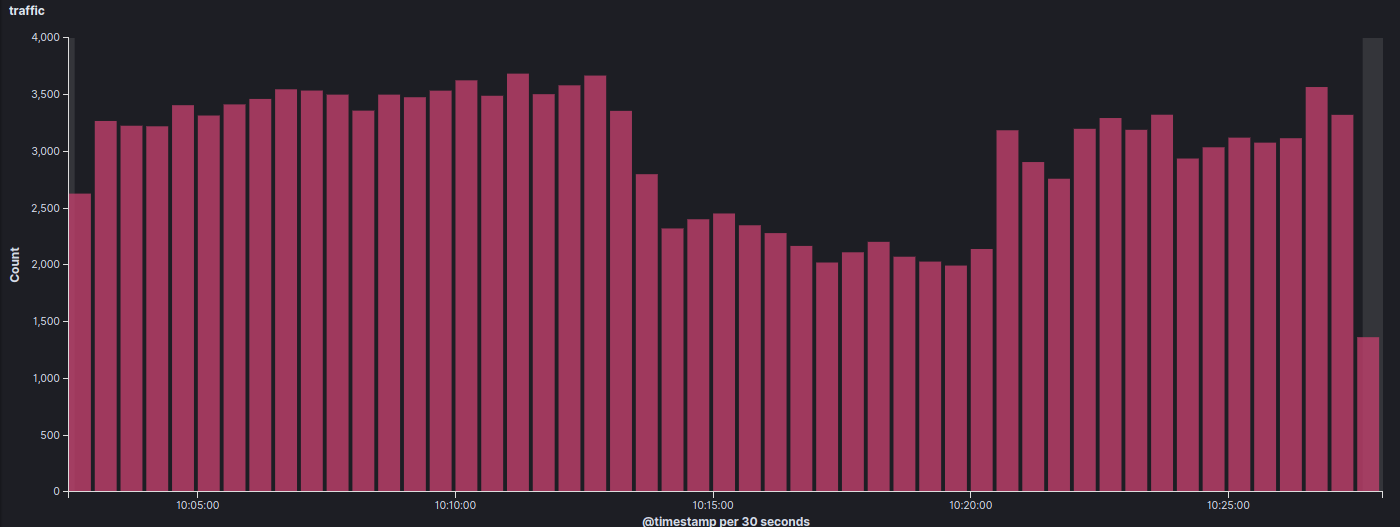
This graph shows a downtime when our runtime servers stopped responding for a few minutes.
And this graph demonstrates that even though the runtime servers were down, the cache layer served most requests.
So, even if a database crashes or the application servers stop responding, the cache keeps responding to 85% of requests.
Improvements to website performance
One of the biggest improvements is in response time. Due to the extended TTL and the optimized processing of cache requests, response time improved substantially.
Here’s some data to help understand the improvement.
- Request to Site with no cache at all responded at 315ms.
- Request to Site loaded with our previous cache solution responded at 30ms.
- Request to Site that loaded from the new cache dedicated server responded at 5ms.
Additional Benefits
In addition to site performance, there were a few other benefits that came along with this update to our cache system, including:
- From the moment we introduced this solution, we’ve seen a load reduction on our servers. Runtime servers that used to receive 100% of traffic now serve only 20% of requests.
- Our database is less loaded and less of a bottleneck in our architecture for runtime sites. If there’s a problem in the database, it will not have an immediate effect on runtime sites.
- Overall, it’s easier to examine performance problems in runtime servers. Previously, if we had performance issues in the runtime server, it was hard to separate the cache requests from the render requests. Now, when most of the requests in runtime servers are for rendered pages and not cached data, it’s easier to find bottlenecks and issues.
Stay tuned for more updates and improvements to Duda' architecture soon!